A Statistical Theory of Overfitting for Imbalanced Classification
Jan 1, 2026· ,,·
0 min read
,,·
0 min read
Jingyang Lyu
Kangjie Zhou
Yiqiao Zhong
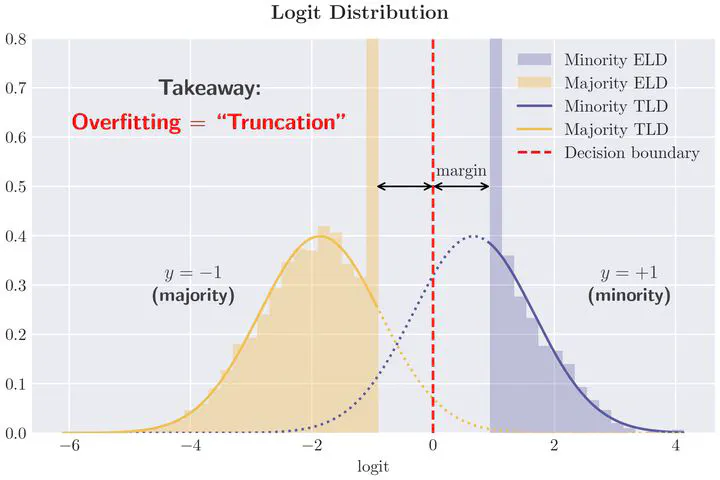 Empirical Logit Distribution (ELD) and Testing Logit Distribution (TLD)
Empirical Logit Distribution (ELD) and Testing Logit Distribution (TLD)Abstract
Classification with imbalanced data is a common challenge in machine learning, where minority classes form only a small fraction of the training samples. Classical theory, relying on large-sample asymptotics and finite-sample corrections, is often ineffective in high dimensions, leaving many overfitting phenomena unexplained. In this paper, we develop a statistical theory for high-dimensional imbalanced linear classification, showing that dimensionality induces truncation or skewing effects on the logit distribution, which we characterize via a variational problem. For linearly separable Gaussian mixtures, logits follow $\mathsf{N}(0, 1)$
on the test set but converge to $\max\{\kappa, \mathsf{N}(0, 1)\}$
on the training set—a pervasive phenomenon we confirm on tabular, image, and text data. This phenomenon explains why the minority class is more severely affected by overfitting. We further show that margin rebalancing mitigates minority accuracy drop and provide theoretical insights into calibration and uncertainty quantification.
Type
Publication
The Fourteenth International Conference on Learning Representations